- create Azure Databricks and launch workspace
2. import jupyter notebook into workspace
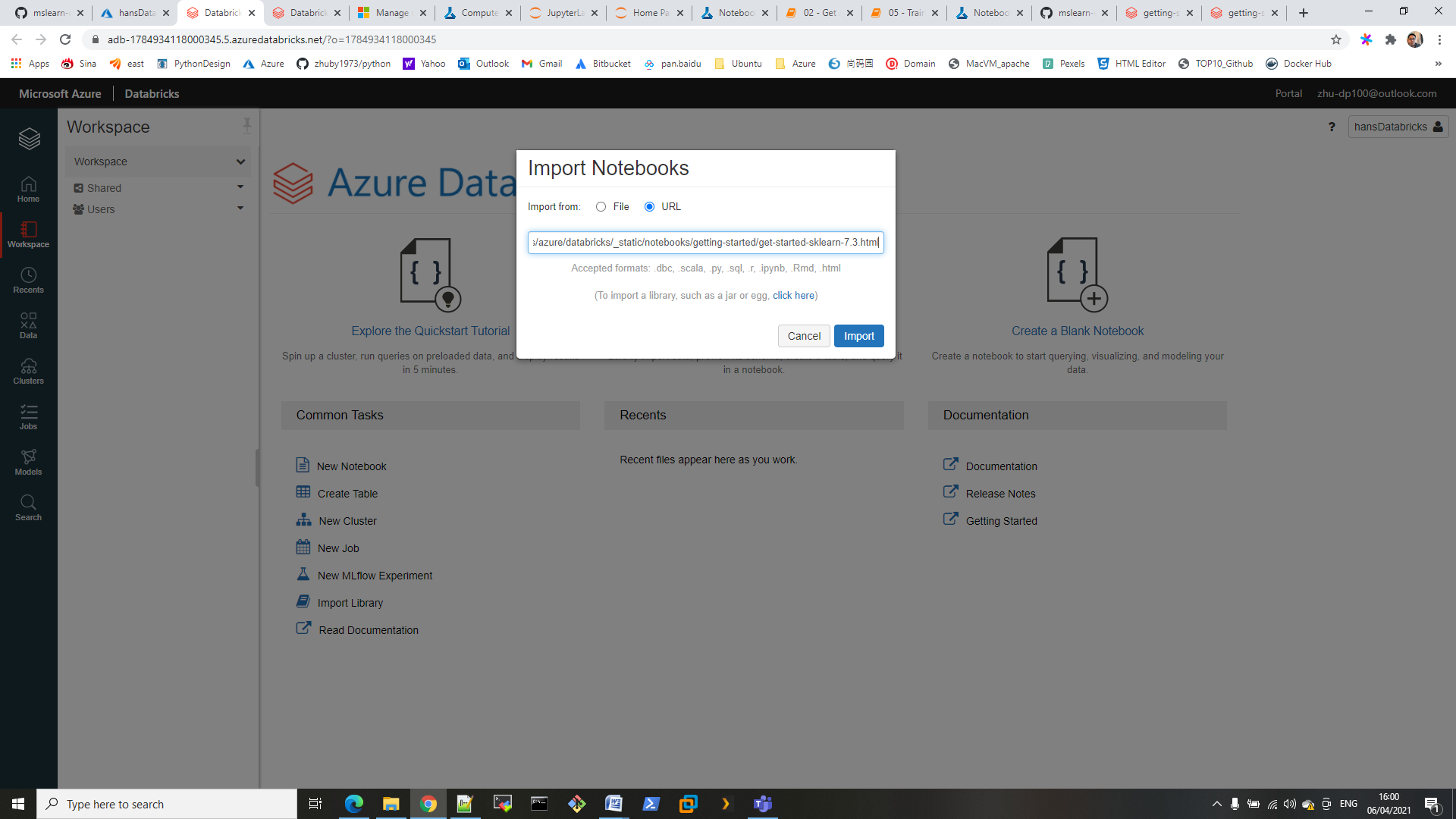
3. create cluster
we can select Databricks Runtime Version: 8.1 ML (includes Apache Spark 3.1.1, Scala 2.12)
Worker Type: Standard_D12_v2
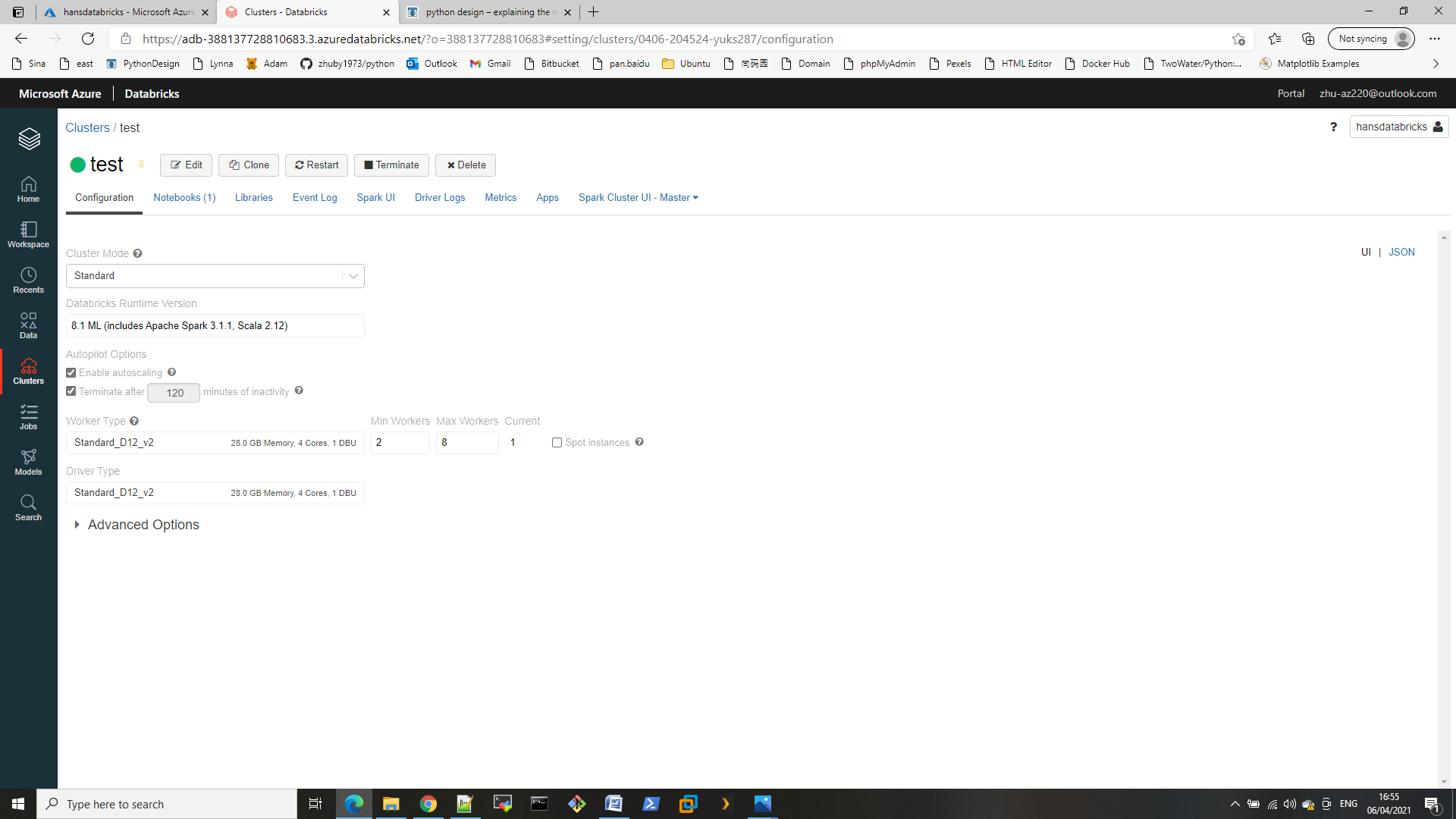
4. Attach the cluster to notebook and click “Run All”