
we will try to use selenium webdriver search in the website and return the article title.
try to search something like "scrapy" on http://pythondesign.ca/ and inspect the elements, you will get something like:
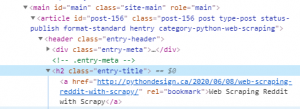
so we can update test_selenium.py as below:
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import time
PATH = "C:\Program Files\chromedriver.exe"
driver = webdriver.Chrome(PATH)
driver.get("http://pythondesign.ca")
print(driver.title)
search = driver.find_element_by_id("search-form-1") # find the search box
search.send_keys("scrapy") # type in the keyword "scrapy"
search.send_keys(Keys.RETURN) # click the search button
#print(driver.page_source) #you can print all the source pages
try:
main = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.ID, "main"))
)
articles = main.find_elements_by_tag_name("article")
for article in articles:
hearder = article.find_element_by_class_name("entry-title")
url = hearder.find_element_by_css_selector('a').get_attribute('href')
print(hearder.text)
print(url)
finally:
driver.quit()test the code:
C:\Users\zhuby\hans>test_selenium.py
DevTools listening on ws://127.0.0.1:61798/devtools/browser/9e65a346-2cdc-4dec-8699-e0a0ac023bf6
python design – explaining the world with python (zhuby1973@gmail.com)
Web Scraping Reddit with Scrapy
http://pythondesign.ca/2020/06/08/web-scraping-reddit-with-scrapy/
access website with selenium webdriver[2]
http://pythondesign.ca/2020/06/08/access-website-with-selenium-webdriver2/