Step 1. install lib:
pip install azure-cognitiveservices-vision-computervision==0.7.0
Step 2. create image-analysis.py and prepare a picture images/street.jpg
from dotenv import load_dotenv
import os
from array import array
from PIL import Image, ImageDraw
import sys
import time
from matplotlib import pyplot as plt
import numpy as np
# Import namespaces
from azure.cognitiveservices.vision.computervision import ComputerVisionClient
from azure.cognitiveservices.vision.computervision.models import VisualFeatureTypes
from msrest.authentication import CognitiveServicesCredentials
def main():
global cv_client
try:
# Get Configuration Settings
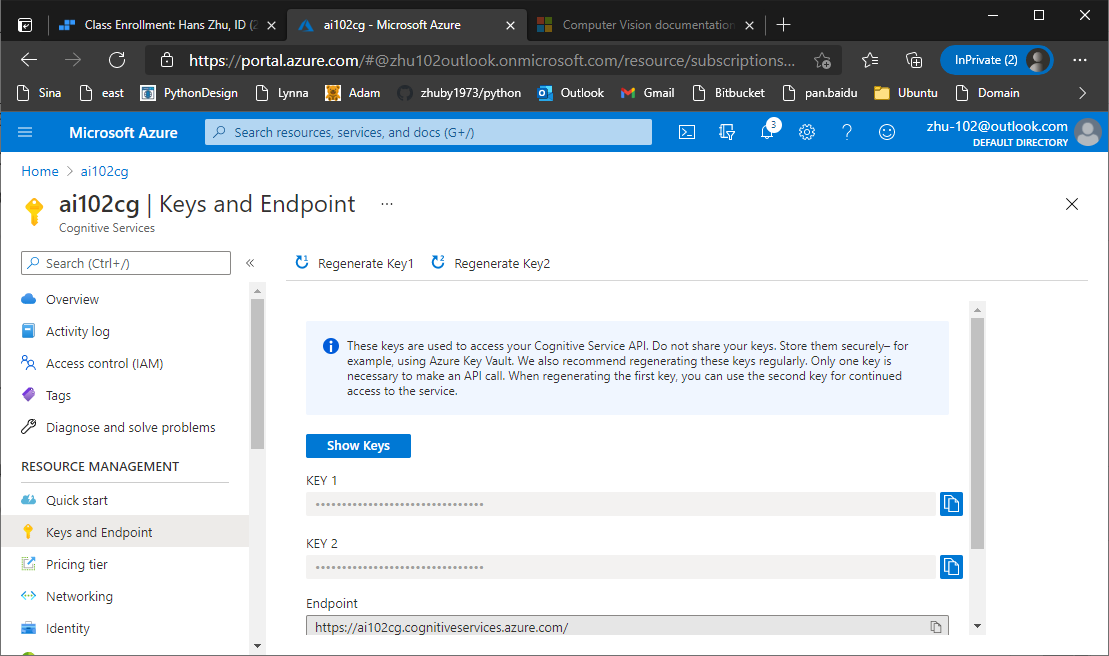
KEY='c36f33fd15784c3984c5a88dcde4c31c'
ENDPOINT='https://ai102cg.cognitiveservices.azure.com/'
# Get image
image_file = 'images/street.jpg'
if len(sys.argv) > 1:
image_file = sys.argv[1]
# Authenticate Computer Vision client
credential = CognitiveServicesCredentials(KEY)
cv_client = ComputerVisionClient(ENDPOINT, credential)
# Analyze image
AnalyzeImage(image_file)
# Generate thumbnail
GetThumbnail(image_file)
except Exception as ex:
print(ex)
def AnalyzeImage(image_file):
print('Analyzing', image_file)
# Specify features to be retrieved
features = [VisualFeatureTypes.description,
VisualFeatureTypes.tags,
VisualFeatureTypes.categories,
VisualFeatureTypes.brands,
VisualFeatureTypes.objects,
VisualFeatureTypes.adult]
# Get image analysis
with open(image_file, mode="rb") as image_data:
analysis = cv_client.analyze_image_in_stream(image_data , features)
# Get image description
for caption in analysis.description.captions:
print("Description: '{}' (confidence: {:.2f}%)".format(caption.text, caption.confidence * 100))
# Get image tags
if (len(analysis.tags) > 0):
print("Tags: ")
for tag in analysis.tags:
print(" -'{}' (confidence: {:.2f}%)".format(tag.name, tag.confidence * 100))
# Get image categories (including celebrities and landmarks)
if (len(analysis.categories) > 0):
print("Categories:")
landmarks = []
celebrities = []
for category in analysis.categories:
# Print the category
print(" -'{}' (confidence: {:.2f}%)".format(category.name, category.score * 100))
if category.detail:
# Get landmarks in this category
if category.detail.landmarks:
for landmark in category.detail.landmarks:
if landmark not in landmarks:
landmarks.append(landmark)
# Get celebrities in this category
if category.detail.celebrities:
for celebrity in category.detail.celebrities:
if celebrity not in celebrities:
celebrities.append(celebrity)
# If there were landmarks, list them
if len(landmarks) > 0:
print("Landmarks:")
for landmark in landmarks:
print(" -'{}' (confidence: {:.2f}%)".format(landmark.name, landmark.confidence * 100))
# If there were celebrities, list them
if len(celebrities) > 0:
print("Celebrities:")
for celebrity in celebrities:
print(" -'{}' (confidence: {:.2f}%)".format(celebrity.name, celebrity.confidence * 100))
# Get brands in the image
if (len(analysis.brands) > 0):
print("Brands: ")
for brand in analysis.brands:
print(" -'{}' (confidence: {:.2f}%)".format(brand.name, brand.confidence * 100))
# Get objects in the image
if len(analysis.objects) > 0:
print("Objects in image:")
# Prepare image for drawing
fig = plt.figure(figsize=(8, 8))
plt.axis('off')
image = Image.open(image_file)
draw = ImageDraw.Draw(image)
color = 'cyan'
for detected_object in analysis.objects:
# Print object name
print(" -{} (confidence: {:.2f}%)".format(detected_object.object_property, detected_object.confidence * 100))
# Draw object bounding box
r = detected_object.rectangle
bounding_box = ((r.x, r.y), (r.x + r.w, r.y + r.h))
draw.rectangle(bounding_box, outline=color, width=3)
plt.annotate(detected_object.object_property,(r.x, r.y), backgroundcolor=color)
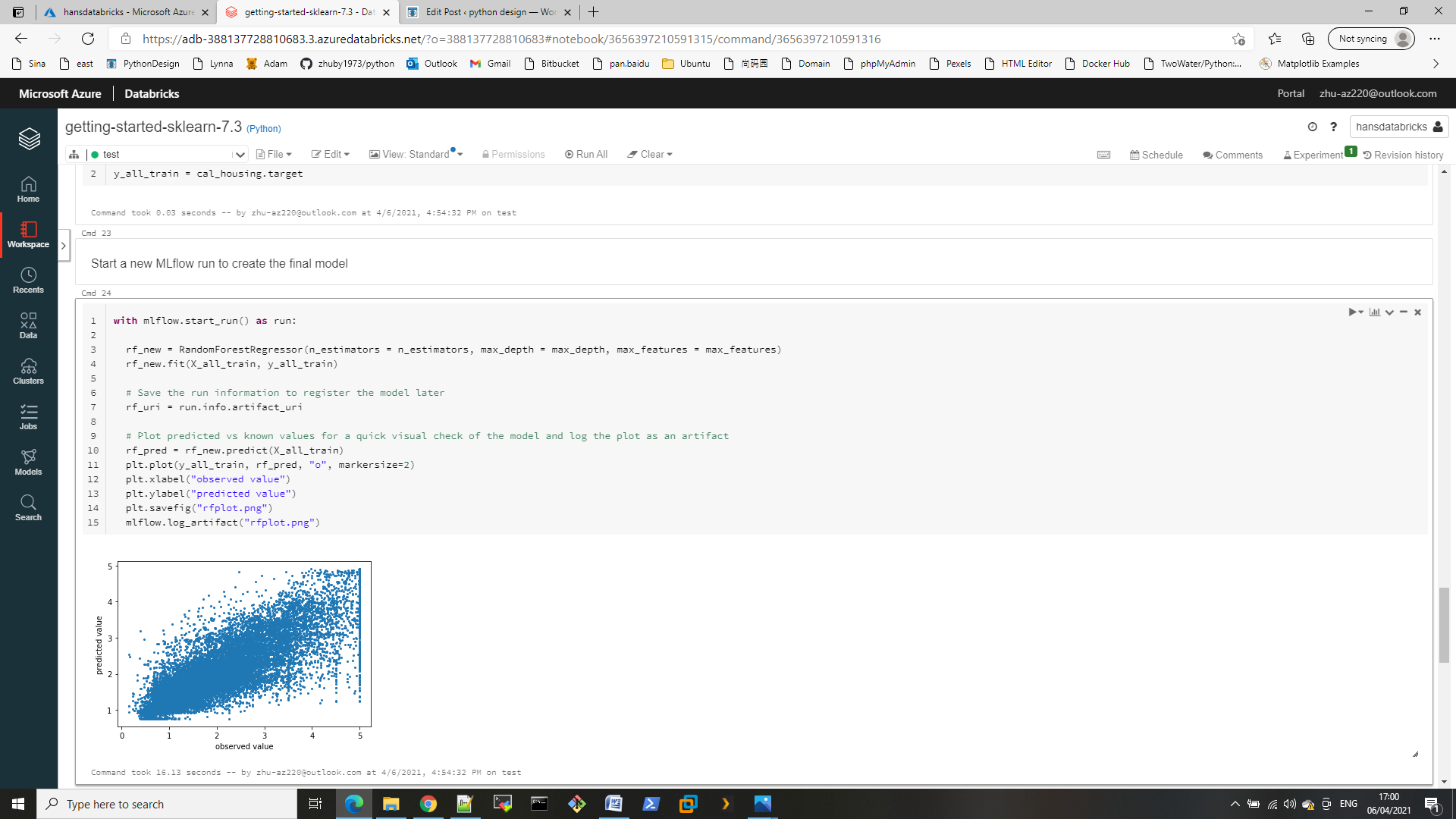
# Save annotated image
plt.imshow(image)
outputfile = 'objects.jpg'
fig.savefig(outputfile)
print(' Results saved in', outputfile)
# Get moderation ratings
ratings = 'Ratings:\n -Adult: {}\n -Racy: {}\n -Gore: {}'.format(analysis.adult.is_adult_content,
analysis.adult.is_racy_content,
analysis.adult.is_gory_content)
print(ratings)
def GetThumbnail(image_file):
print('Generating thumbnail')
# Generate a thumbnail
with open(image_file, mode="rb") as image_data:
# Get thumbnail data
thumbnail_stream = cv_client.generate_thumbnail_in_stream(100, 100, image_data, True)
# Save thumbnail image
thumbnail_file_name = 'thumbnail.png'
with open(thumbnail_file_name, "wb") as thumbnail_file:
for chunk in thumbnail_stream:
thumbnail_file.write(chunk)
print('Thumbnail saved in.', thumbnail_file_name)
if __name__ == "__main__":
main()

Step 3. run it with:
python image-analysis.py images/street.jpg
you will get objects.jpg and thumbnail.png generated in same folder:


ref: https://docs.microsoft.com/en-us/azure/cognitive-services/Face/Quickstarts/client-libraries?pivots=programming-language-python&tabs=visual-studio