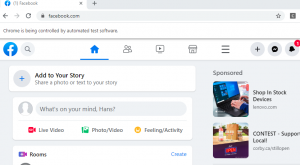
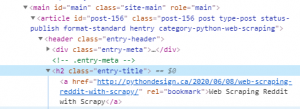
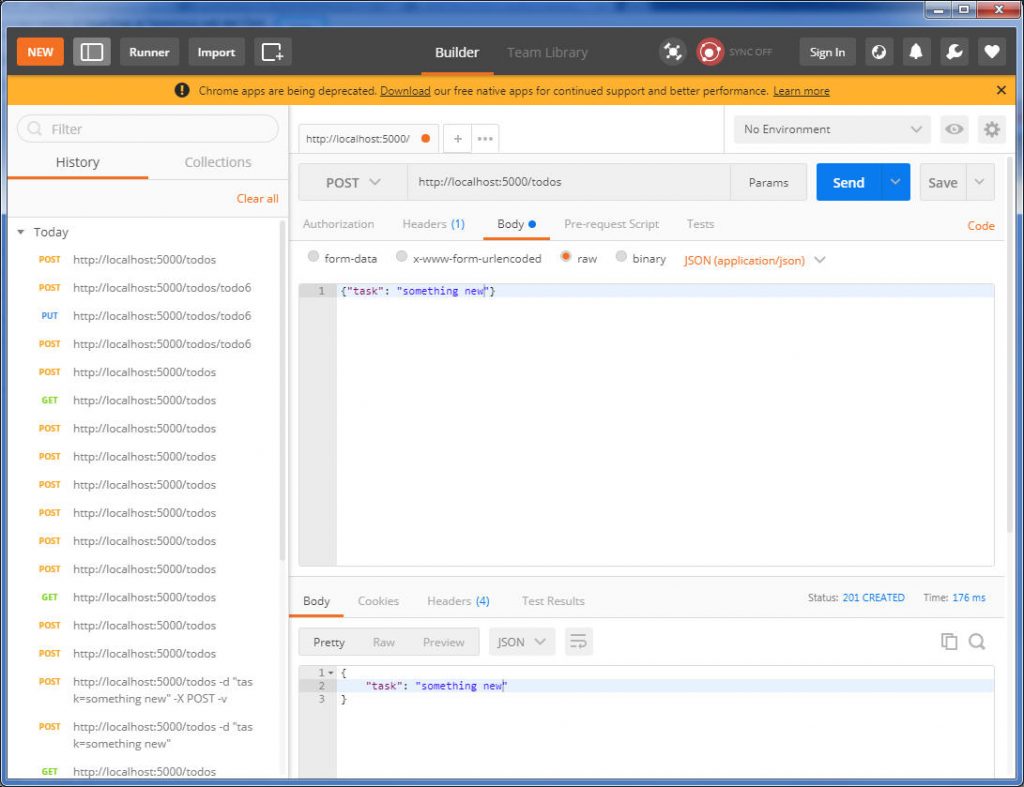
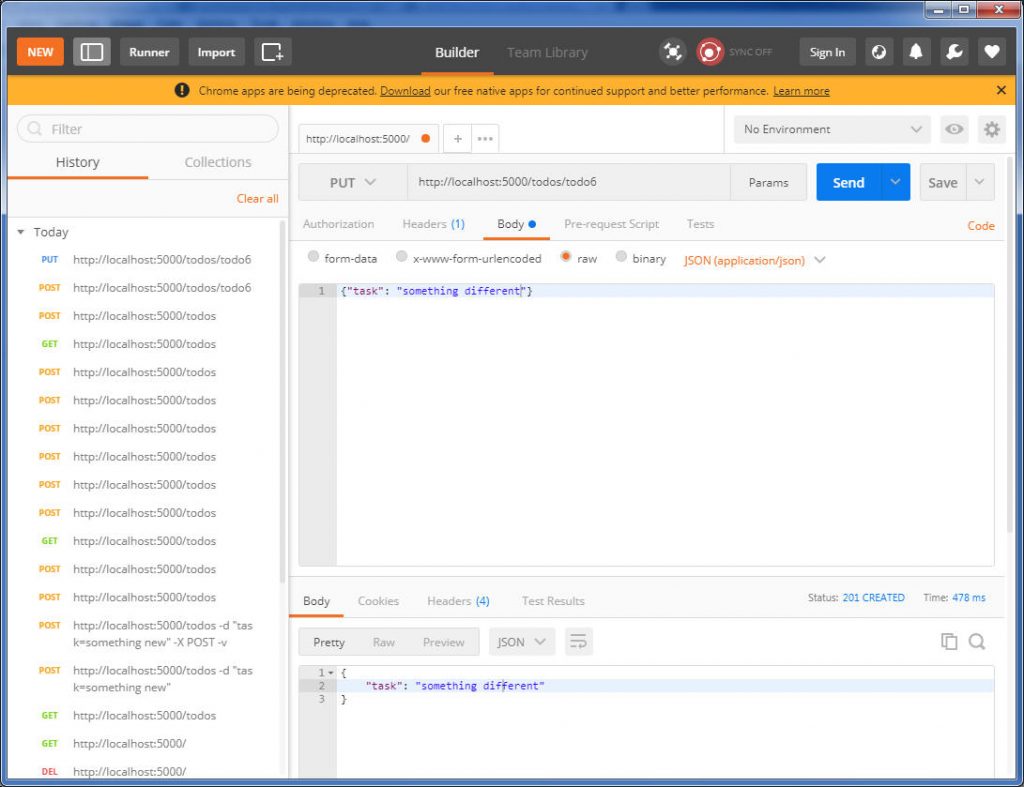
we can use below actions for webpage navigating:
- driver.find_element_by_link_text(“Selenium Automate Your Login Process”)
- driver.implicitly_wait(30)
- driver.back()
- driver.forward()
- main.find_element_by_id(‘submit’).click()
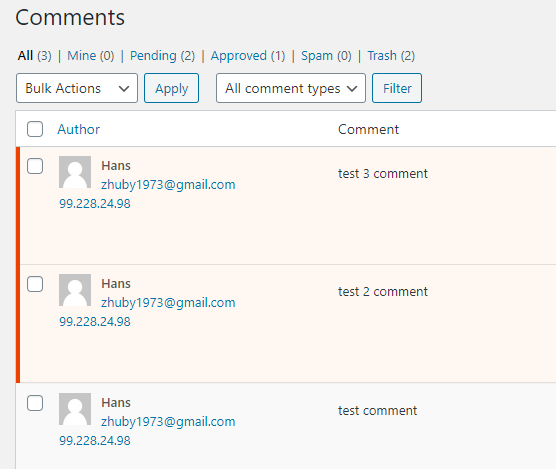
C:\Users\zhuby\hans>page_nav.pyDevTools listening on ws://127.0.0.1:53533/devtools/browser/94c2afb2-731a-4d62-baa6-7b46d0f24fcd python design – explaining the world with python (zhuby1973@gmail.com) and you will find your comments has been posted to the site:
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import time
PATH = "C:\Program Files\chromedriver.exe"
driver = webdriver.Chrome(PATH)
driver.get("http://pythondesign.ca")
print(driver.title)
driver.implicitly_wait(30)
link = driver.find_element_by_link_text("Selenium Automate Your Login Process")
link.click()
try:
main = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.ID, "commentform"))
)
main.find_element_by_id('comment').click()
main.find_element_by_id('comment').send_keys('test 3 comment')
main.find_element_by_id('author').click()
main.find_element_by_id('author').send_keys('Hans')
main.find_element_by_id('email').click()
main.find_element_by_id('email').send_keys('zhuby1973@gmail.com')
main.find_element_by_id('submit').click()
driver.back()
driver.forward()
finally:
driver.quit()
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import time
PATH = "C:\Program Files\chromedriver.exe"
driver = webdriver.Chrome(PATH)
driver.get("http://pythondesign.ca")
print(driver.title)
driver.implicitly_wait(30)
link = driver.find_element_by_link_text("Selenium Automate Your Login Process")
link.click()
try:
main = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.ID, "commentform"))
)
main.find_element_by_id('comment').click()
main.find_element_by_id('comment').send_keys('test 3 comment')
main.find_element_by_id('author').click()
main.find_element_by_id('author').send_keys('Hans')
main.find_element_by_id('email').click()
main.find_element_by_id('email').send_keys('zhuby1973@gmail.com')
main.find_element_by_id('submit').click()
driver.back()
driver.forward()
finally:
driver.quit()
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import time
PATH = "C:\Program Files\chromedriver.exe"
driver = webdriver.Chrome(PATH)
driver.get("http://pythondesign.ca")
print(driver.title)
driver.implicitly_wait(30)
link = driver.find_element_by_link_text("Selenium Automate Your Login Process")
link.click()
try:
main = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.ID, "commentform"))
)
main.find_element_by_id('comment').click()
main.find_element_by_id('comment').send_keys('test 3 comment')
main.find_element_by_id('author').click()
main.find_element_by_id('author').send_keys('Hans')
main.find_element_by_id('email').click()
main.find_element_by_id('email').send_keys('zhuby1973@gmail.com')
main.find_element_by_id('submit').click()
driver.back()
driver.forward()
finally:
driver.quit()