Step 1: install OpenLDAP Server
sudo apt update
sudo apt -y install slapd ldap-utils
During the installation, you’ll be prompted to set LDAP admin password.
You can confirm that your installation was successful using the commandslapcat to output SLAPD database contents:
root@ubunu2004:~# slapcat
dn: dc=linuxvmimagrs,dc=local
objectClass: top
objectClass: dcObject
objectClass: organization
o: linuxvmimagrs.local
dc: linuxvmimagrs
structuralObjectClass: organization
entryUUID: a95871c2-5a53-103a-961d-11b344dacd95
creatorsName: cn=admin,dc=linuxvmimagrs,dc=local
createTimestamp: 20200714192629Z
entryCSN: 20200714192629.414835Z#000000#000#000000
modifiersName: cn=admin,dc=linuxvmimagrs,dc=local
modifyTimestamp: 20200714192629Z
dn: cn=admin,dc=linuxvmimagrs,dc=local
objectClass: simpleSecurityObject
objectClass: organizationalRole
cn: admin
description: LDAP administrator
Step 2: Add base dn for Users and Groups
Create a file named basedn.ldif with below contents:
dn: ou=people,dc=linuxvmimagrs,dc=local
objectClass: organizationalUnit
ou: people
dn: ou=groups,dc=linuxvmimagrs,dc=local
objectClass: organizationalUnit
ou: groups
Now add the file by running the command:
ldapadd -x -D cn=admin,dc=linuxvmimagrs,dc=local -W -f basedn.ldif
Step 3: Add User Accounts and Groups
root@ubunu2004:~# slappasswd
New password:
Re-enter new password:
{SSHA}QCjJfk3CTNWJayd0UJrN7Hf+A/rpwquD
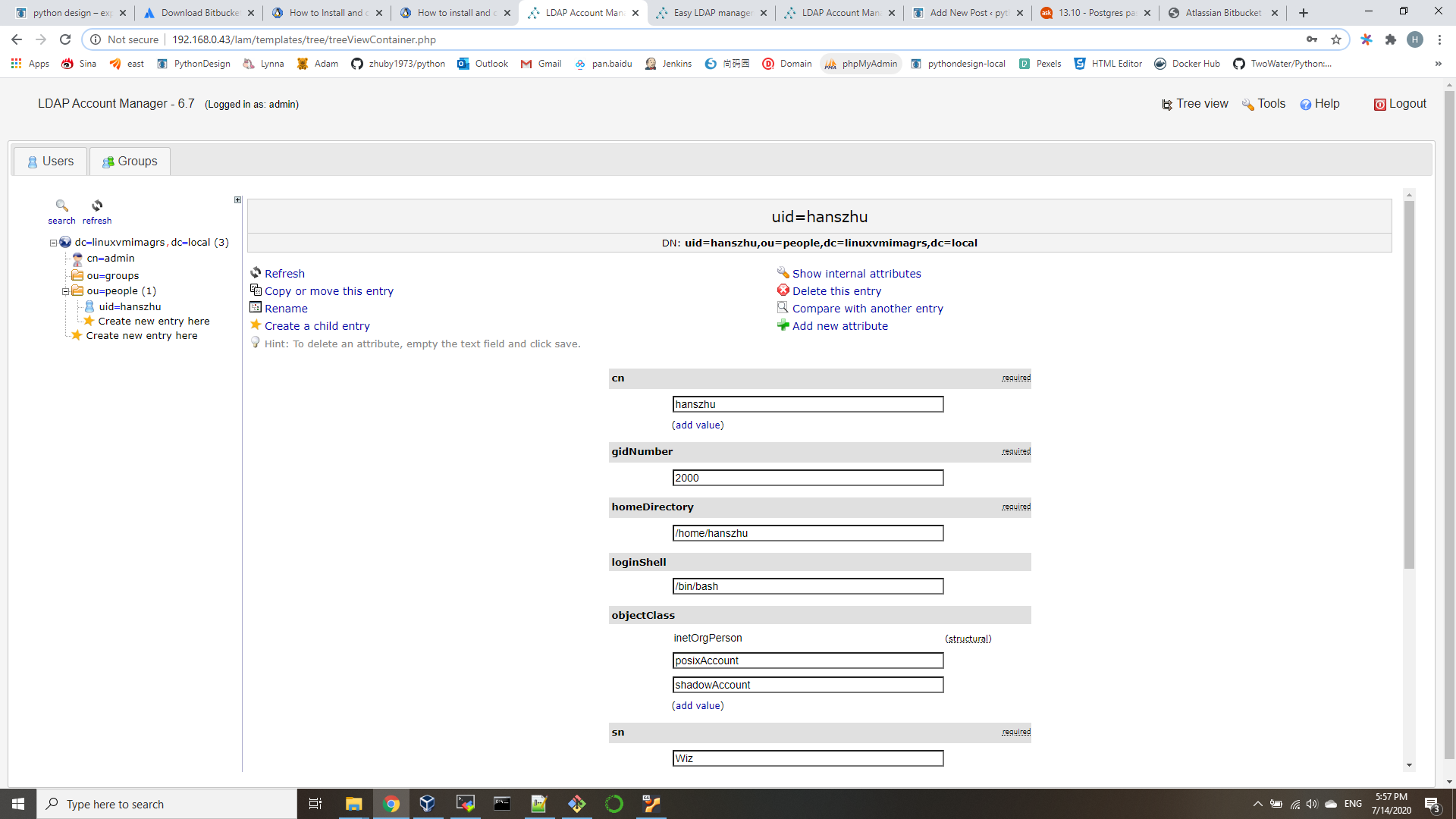
Create user.ldif file for adding users:
dn: uid=hanszhu,ou=people,dc=linuxvmimagrs,dc=local
objectClass: inetOrgPerson
objectClass: posixAccount
objectClass: shadowAccount
cn: hanszhu
sn: Wiz
userPassword: {SSHA}QCjJfk3CTNWJayd0UJrN7Hf+A/rpwquD
loginShell: /bin/bash
uidNumber: 2000
gidNumber: 2000
homeDirectory: /home/hanszhuadd account by running:
ldapadd -x -D cn=admin,dc=linuxvmimagrs,dc=local -W -f user.ldif
Step 4: Install LDAP Account Manager
we need PHP and Apache web server for LDAP Account Manager.
sudo apt -y install ldap-account-manager
review /etc/apache2/conf-enabled/ldap-account-manager.conf
sudo systemctl restart apache2
Step 5: Configure LDAP Account Manager
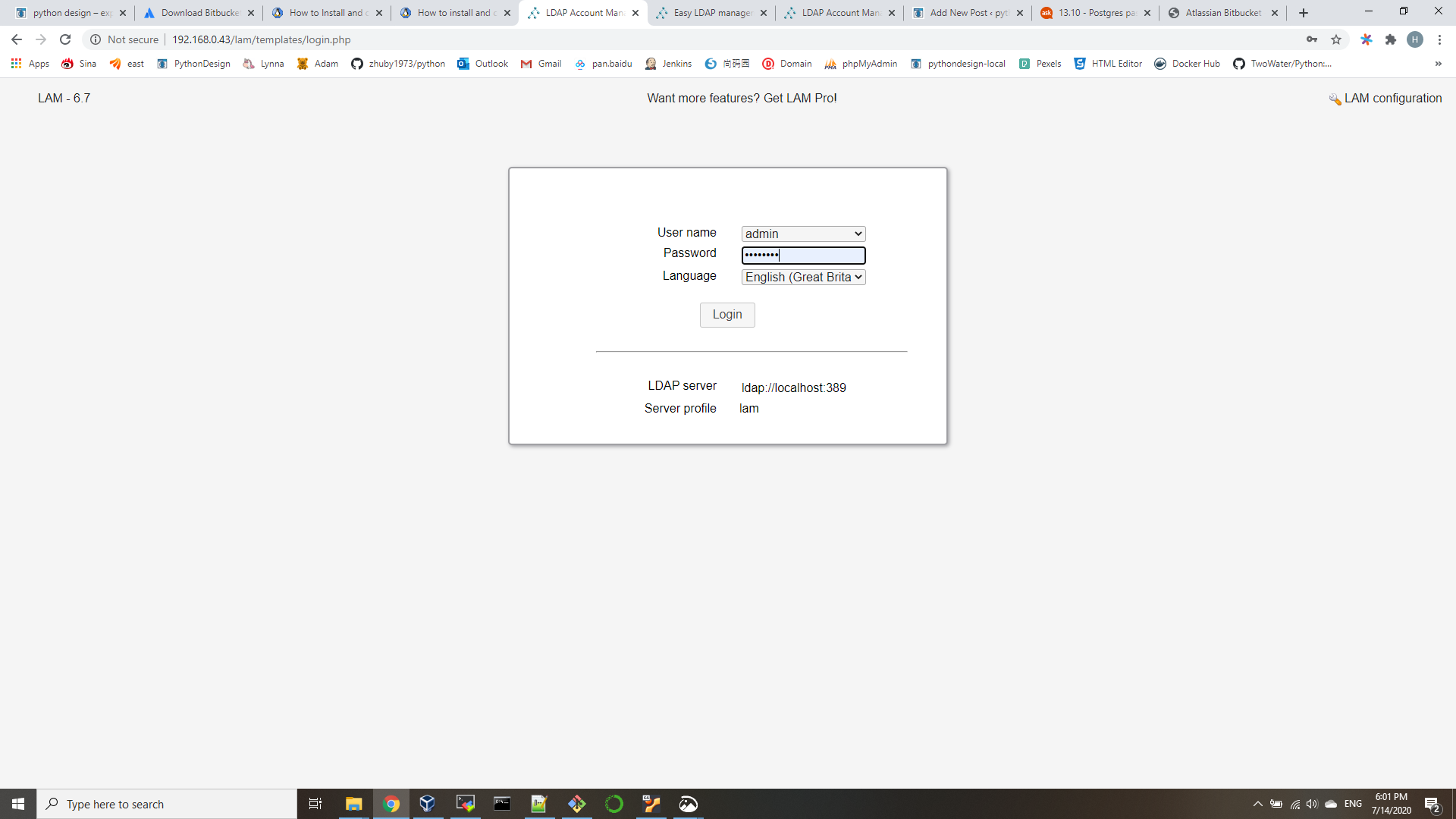
open http://192.168.0.43/lam
We need to set our LDAP server profile by clicking on[LAM configuration] at the upper right corner. default password is lam.

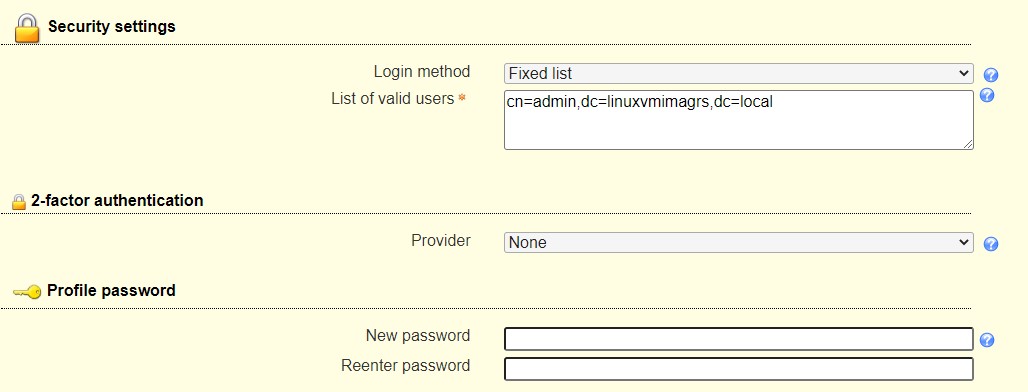
then you can save and logon lam with your LDAP admin ID: