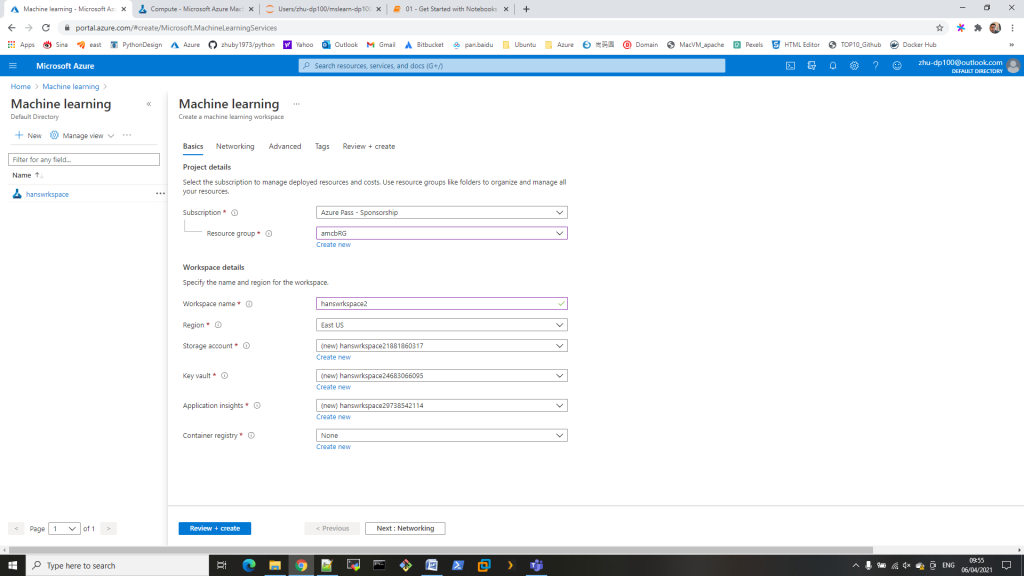
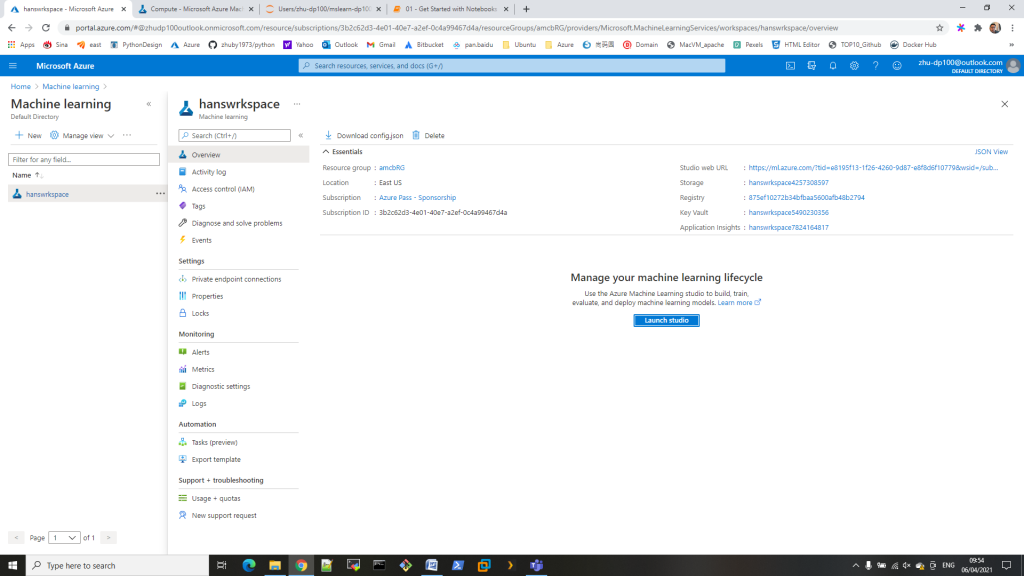
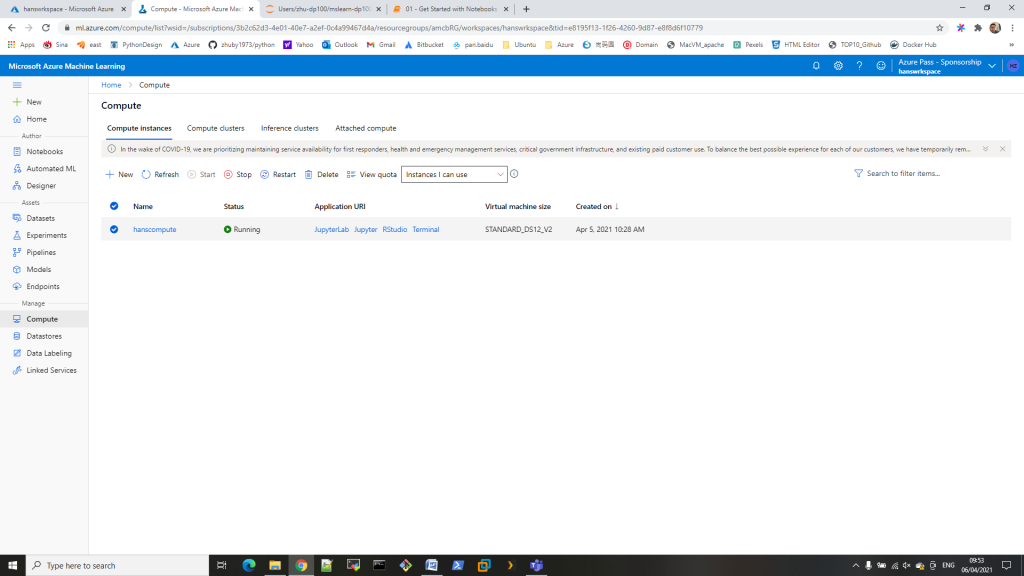
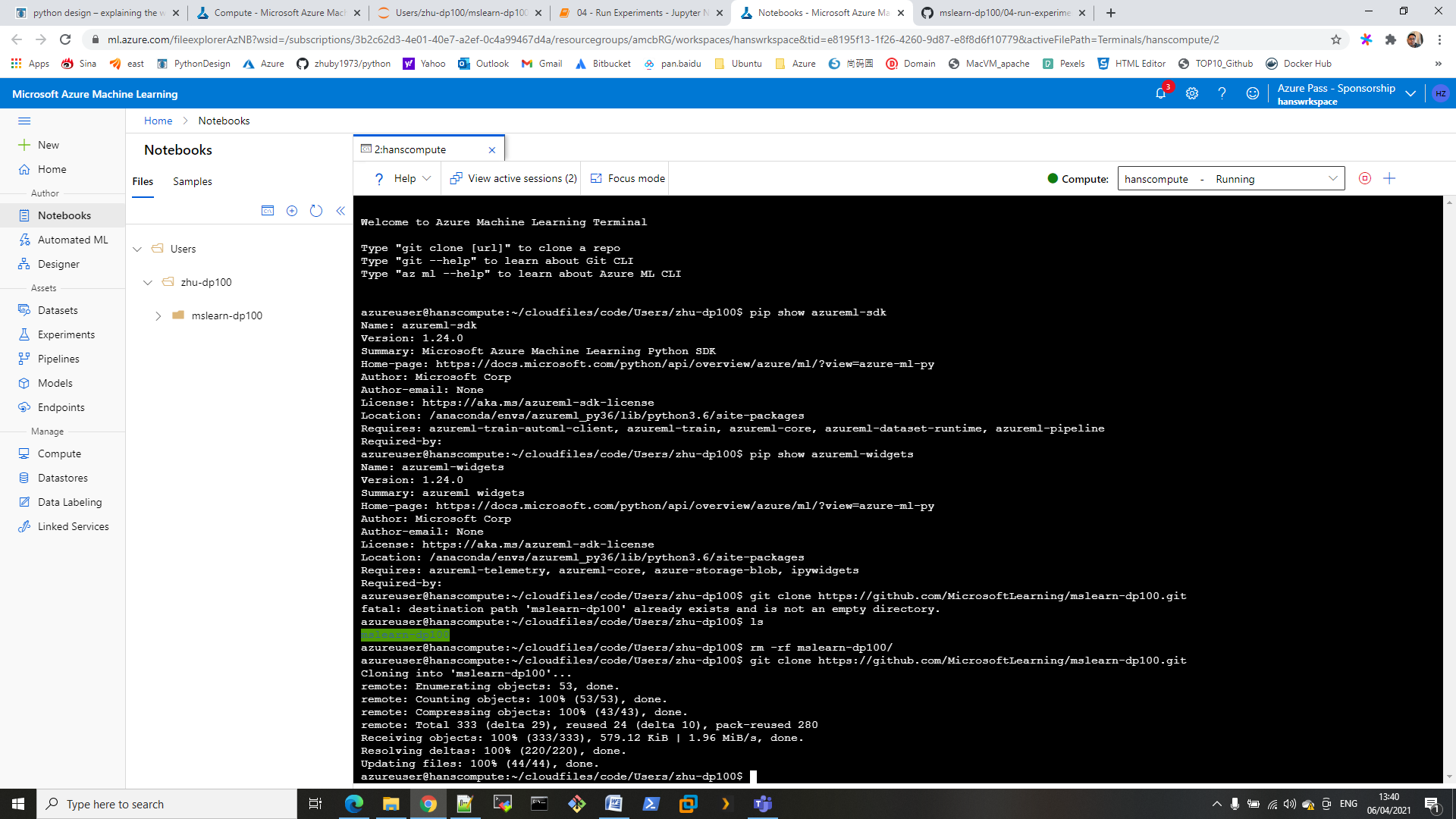
STEP5 : start docker compose with command “docker-compose up”
ubuntu@ubuntu2004:~/Django_Compose$ docker-compose up
Starting django_compose_db_1 ... done
Starting django_compose_web_1 ... done
Attaching to django_compose_db_1, django_compose_web_1
db_1 |
db_1 | PostgreSQL Database directory appears to contain a database; Skipping initialization
db_1 |
db_1 | 2021-03-11 17:34:58.762 UTC [1] LOG: starting PostgreSQL 13.2 (Debian 13.2-1.pgdg100+1) on x86_64-pc-linux-gnu, compiled by gcc (Debian 8.3.0-6) 8.3.0, 64-bit
db_1 | 2021-03-11 17:34:58.762 UTC [1] LOG: listening on IPv4 address "0.0.0.0", port 5432
db_1 | 2021-03-11 17:34:58.763 UTC [1] LOG: listening on IPv6 address "::", port 5432
db_1 | 2021-03-11 17:34:58.765 UTC [1] LOG: listening on Unix socket "/var/run/postgresql/.s.PGSQL.5432"
db_1 | 2021-03-11 17:34:58.770 UTC [25] LOG: database system was shut down at 2021-03-11 17:25:27 UTC
db_1 | 2021-03-11 17:34:58.775 UTC [1] LOG: database system is ready to accept connections
web_1 | Watching for file changes with StatReloader
web_1 | Performing system checks...
web_1 |
web_1 | System check identified no issues (0 silenced).
web_1 |
web_1 | You have 18 unapplied migration(s). Your project may not work properly until you apply the migrations for app(s): admin, auth, contenttypes, sessions.
web_1 | Run 'python manage.py migrate' to apply them.
web_1 | March 11, 2021 - 17:35:00
web_1 | Django version 3.1.7, using settings 'composeexample.settings'
web_1 | Starting development server at http://0.0.0.0:8000/
Face detection using Haar cascades is a machine learning based approach where a cascade function is trained with a set of input data. OpenCV already contains many pre-trained classifiers for face, eyes, smiles, etc.. Today we will be using the face classifier. You can experiment with other classifiers as well. You need to download the trained classifier XML file (haarcascade_frontalface_default.xml), which is available in OpenCv’s GitHub repository. Save it to your working location.
download logo.jpg from internet
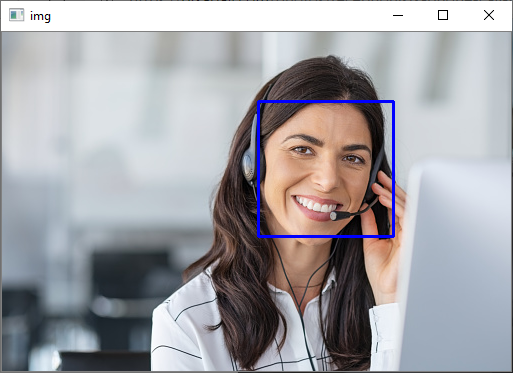
4. python3 code to detect faces in image
import cv2
# Load the cascade
#face_cascade = cv2.CascadeClassifier('haarcascade_frontalface_default.xml')
face_cascade = cv2.CascadeClassifier(cv2.data.haarcascades + "haarcascade_frontalface_default.xml")
# Read the input image
img = cv2.imread('logo.jpg')
# Convert into grayscale
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# Detect faces
faces = face_cascade.detectMultiScale(gray, 1.1, 4)
# Draw rectangle around the faces
for (x, y, w, h) in faces:
cv2.rectangle(img, (x, y), (x+w, y+h), (255, 0, 0), 2)
crop_face = img[y:y + h, x:x + w]
# save faces
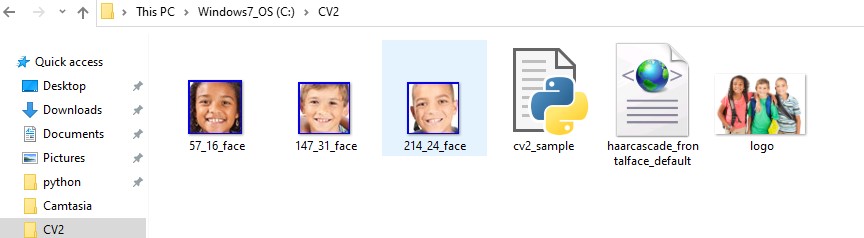
cv2.imwrite(str(x) + '_' + str(y) + '_face.jpg', crop_face)
# Display the output
cv2.imshow('img', img)
cv2.imshow("imgcropped", crop_face)
cv2.waitKey()
5. run it with pythoh cv2_sample.py, you will find faces detected and cropped faces saved:
install Apache and WSGI sudo apt install apache2 libapache2-mod-wsgi-py3 python3-pip python3-virtualenv sudo pip3 install flask (skip this if you are planning to setup venv)
enable mod_wsgi sudo a2enmod wsgi
create files as below (the __init__.py and wsgi file are mandatory)
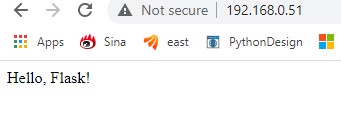
6. restart apache and verify the app systemctl restart apache2 then you can open http://192.168.0.51/
NOTE: if you want use python virtual env, we can setup venv in /var/www/FLASKAPPS: virtualenv venv source venv/bin/activate pip install flask then update WSGIDaemonProcess in /etc/apache2/sites-available/flaskhelloworldsite.com.conf with python-home: WSGIDaemonProcess helloworldapp user=www-data group=www-data threads=5 python-home=/var/www/FLASKAPPS/venv
right click Command Prompt and select“Run as Administrator”. At the prompt, type the following command: wmic
in wmic prompt, you can use below command to list apps you installed: product get name
command to uninstall, don’t forget to confirm with Y: product where name=”program name” call uninstall
wmic:root\cli>product where name="Oracle VM VirtualBox 6.1.10" call uninstall
Execute (\\HANS-T430\ROOT\CIMV2:Win32_Product.IdentifyingNumber="{0359AF05-E674-4ED4-B9FB-B77918617667}",Name="Oracle VM VirtualBox 6.1.10",Vendor="Oracle Corporation",Version="6.1.10")->Uninstall() (Y/N/?)? Y
Method execution successful.
Out Parameters:
instance of __PARAMETERS
{
ReturnValue = 1618;
};
NOTE: we can use PowerShell command to remove Win10 built-in apps, use GameServices as example: Get-AppxPackage -AllUsers Microsoft.XboxGamingOverlay | Remove-AppxPackage ref: https://www.majorgeeks.com/content/page/remove_windows_10_apps_using_powershell.html
from flask import Flask
from flask_sqlalchemy import SQLAlchemy
app = Flask(__name__)
app.config['SQLALCHEMY_DATABASE_URI'] = 'sqlite:///users.sqlite3'
app.config['SECRET_KEY'] = "op23413kjkjljlksjfaksjfdlksajfkjlkjlkjk"
app.config['SQLALCHEMY_TRACK_MODIFICATIONS'] = False
db = SQLAlchemy(app)
class User(db.Model):
__tablename__ = 'users'
username = db.Column(db.String(64), primary_key=True)
passwd = db.Column(db.String(64))
def __repr__(self):
return '<User %r>' % self.username
if __name__ == "__main__":
db.create_all()
app.run("0.0.0.0", 8090, debug=True)
2. test hello.py with python3 shell
zhub2@apache-vm1:~ $ python3
>>> from hello import db
>>> db.create_all()
>>> from hello import User
### INSERT NEW User
>>> user_john = User(username='john', passwd='carlos23')
>>> db.session.add(user_john)
>>> db.session.commit()
### LIST ALL User
>>> User.query.all()
[<User 'john'>]
### UPDATE User WHERE username='john'
>>> user_john = User.query.filter_by(username='john').first()
>>> user_john.passwd='test123'
>>> db.session.add(user_john)
>>> db.session.commit()
Create an Azure service principal using the Azure CLI
PS /home/linda> az ad sp create-for-rbac --role="Contributor" --scopes="/subscriptions/528e05db-6ee0-43a6-9f5a-10cf3fac9f1c"
Creating 'Contributor' role assignment under scope '/subscriptions/528e05db-6ee0-43a6-9f5a-10cf3fac9f1c'
Retrying role assignment creation: 1/36
The output includes credentials that you must protect. Be sure that you do not include these credentials in your code or check the credentials into your source control. For more information, see https://aka.ms/azadsp-cli
{
"appId": "bb933f07-1544-4acf-9e6b",
"displayName": "azure-cli-2021-02-01-15-53-30",
"name": "http://azure-cli-2021-02-01-15-53-30",
"password": "Cc84DM4qAHJrwEb1.",
"tenant": "a9b214e8-0697-4c29-886f-e89844c78dbd"
}
2. Login using an Azure service principal az login –service-principal -u “***” -p “***” –tenant “***”
3. Set the current Azure subscription az account show az account list –query “[].{name:name, subscriptionId:id}” az account set –subscription=””
4. Create a Terraform configuration file
# Configure the Microsoft Azure Provider
# client_id="appId" and client_secret = "password" when you create service principal
provider "azurerm" {
subscription_id = "528e05db-6ee0-43a6-9f5a-10cf3fac9f1c"
client_id = "bb933f07-1544-4acf-9e6b"
client_secret = "Cc84DM4qAHJrwEb1."
tenant_id = "a9b214e8-0697-4c29-886f-e89844c78dbd"
features {}
}
# Create a resource group if it doesn't exist
resource "azurerm_resource_group" "myterraformgroup" {
name = "myResourceGroup"
location = "eastus"
tags = {
environment = "Terraform Demo"
}
}
5. Create and apply a Terraform execution plan terraform init terraform plan -out terraform_plan.tfplan terraform apply “terraform_plan.tfplan”
PS /home/linda> terraform plan -out terraform_plan.tfplan
An execution plan has been generated and is shown below.
Resource actions are indicated with the following symbols:
+ create
Terraform will perform the following actions:
# azurerm_resource_group.myterraformgroup will be created
+ resource "azurerm_resource_group" "myterraformgroup" {
+ id = (known after apply)
+ location = "eastus"
+ name = "myResourceGroup"
+ tags = {
+ "environment" = "Terraform Demo"
}
}
Plan: 1 to add, 0 to change, 0 to destroy.
------------------------------------------------------------------------
This plan was saved to: terraform_plan.tfplan
To perform exactly these actions, run the following command to apply:
terraform apply "terraform_plan.tfplan"
PS /home/linda> terraform apply "terraform_plan.tfplan"
azurerm_resource_group.myterraformgroup: Creating...
azurerm_resource_group.myterraformgroup: Creation complete after 1s [id=/subscriptions/528e05db-6ee0-43a6-9f5a-10cf3fac9f1c/resourceGroups/myResourceGroup]
Apply complete! Resources: 1 added, 0 changed, 0 destroyed.
Gevent is the use of simple, sequential programming in python to achieve scalability provided by asynchronous IO and lightweight multi-threading (as opposed to the callback-style of programming using Twisted’s Deferred). It is built on top of libevent/libev (for asynchronous I/O) and greenlets (lightweight cooperative multi-threading). we can use pip install gevent to install it. Here is the sample.py:
from gevent import monkey
monkey.patch_all()
from flask import Flask
from gevent import pywsgi
app = Flask(__name__)
@app.route('/')
def hello():
return "Hello World!"
if __name__ == '__main__':
#app.run()
server = pywsgi.WSGIServer(("0.0.0.0", 8080), app)
server.serve_forever()
you can run it in background: nohup python3 sample.py & then you can open the sample app on http://your_server_ip:8080
Use ApacheBench To Do Load Testing: 1. apt-get install apache2-utils 2. ab -r -n 2000 -c 200 http://127.0.0.1:8080/?delay=1
Concurrency Level: 200
Time taken for tests: 2.470 seconds
Complete requests: 2000
Failed requests: 0
Total transferred: 294000 bytes
HTML transferred: 24000 bytes
Requests per second: 809.60 [#/sec] (mean)
Time per request: 247.035 [ms] (mean)
Time per request: 1.235 [ms] (mean, across all concurrent requests)
Transfer rate: 116.22 [Kbytes/sec] received
compare it with sample_old.py without gevent:
from flask import Flask
app = Flask(__name__)
@app.route('/')
def hello():
return "Hello World!"
if __name__ == '__main__':
app.run(port=8080)
run same ab command, you will get:
Concurrency Level: 200
Time taken for tests: 4.493 seconds
Complete requests: 2000
Failed requests: 0
Total transferred: 330000 bytes
HTML transferred: 24000 bytes
Requests per second: 445.10 [#/sec] (mean)
Time per request: 449.340 [ms] (mean)
Time per request: 2.247 [ms] (mean, across all concurrent requests)
Transfer rate: 71.72 [Kbytes/sec] received